06 Aug 2018
Correct weighting for regression analysis in analytical calibration
Chromatographic methods often require that the analyte response is calibrated (and validated) over a wide concentration range when the analyte concentration in the sample is either unknown or is expected to vary widely. Bioanalysis, environmental and clinical applications are just a few examples of where this may be the case.
No matter how linear the detector response, the need to cover wide concentration ranges can present us with problems with homoscedasticity or the assumption that variance is equal across the whole calibration range, independent of analyte concentration. In fact the use of fitted regression models using least-squares estimators requires this to be the case in order to give unbiased estimates of the concentration of our unknowns.
This problem typically presents itself as poor accuracy (bias) when determining smaller analyte concentrations as the higher concentration data tends to have larger variance which unfairly influences (weights) the regression model.
Once problems with homoscedasticity of the data have been identified and confirmed, it is often relatively straightforward to overcome the issues using weighted least squares linear regression models, however there tends to be a reluctance or nervousness in this approach. It’s almost as though unless we use unweighted linear regression models, we fear challenge to an ‘atypical’ approach and the use of non-linear or weighted models will draw extra scrutiny that will be very difficult to justify and we are somehow trying to use mathematics to overcome issues with our methods. I’ve seen people re-develop methods in order to try and overcome these issues, wasting a lot of time and effort.
We simply need to accept that some analytical methods do not produce a linear response and, as we will examine here, that the data may not have equal variance which is independent of analyte concentration and that under these circumstances the use of weighted regression models is required. I believe the main ‘fear’ in the use of these ‘less conventional models’ is the burden of justifying the approach and hopefully I can demonstrate with a relevant example that, for the use of weighted regression at least, the justification can be relatively straightforward.
So here is the data for the calibration curve under investigation;
| Std Amount (µg/ml) | Response Factor (Area Response Analyte / Area Response Internal Standard) |
| 0.0050 | 0.0226 |
| 0.0100 | 0.0483 |
| 0.0200 | 0.1023 |
| 0.0500 | 0.2668 |
| 0.4995 | 2.4535 |
| 1.9982 | 11.3321 |
| 5.9945 | 39.0320 |
Table 1: Calibration data.
The unweighted least squares regression model output is;
Slope (a) = 6.4916
Intercept (b) = -0.3461
Coefficient of determination, r2 = 0.9980
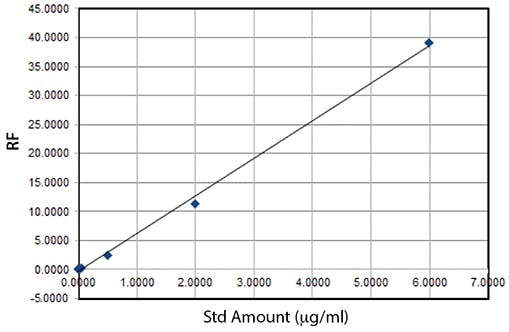
Figure 1: Unweighted linear regression model for the data in Table 1
On the face of it, the regression co-efficient (r2) seems to indicate linearity and the data seems to fit the regression model (trend line in Figure 1).
However, a simple ‘eyeball’ of the regression results does not allow us to properly investigate the validity of the model.
Due to some prior knowledge of the application and likely sample concentration ranges the following data was produced in order to the test the regression model.
The % Relative Error allows a quantitative estimate of the error in each determination and is calculated as follows;
%RE = ((Calculated Concentration - Nominal Concentration) / Nominal Concentration) x 100
| Std Amount (µg/ml) | Response Factor | Calculated Conc (µg/ml) | % Relative Error |
| 0.01 | 0.05481 | 0.06175 | 517.5 |
| 0.01 | 0.056827 | 0.06206 | 520.6 |
| 0.01 | 0.054594 | 0.06172 | 517.2 |
| 0.01 | 0.05601 | 0.06194 | 519.4 |
| 0.01 | 0.054834 | 0.06175 | 517.5 |
| 0.02 | 0.114981 | 0.07102 | 255.1 |
| 0.02 | 0.114369 | 0.07093 | 254.6 |
| 0.02 | 0.110921 | 0.07039 | 252.0 |
| 0.02 | 0.11422 | 0.07090 | 254.5 |
| 0.02 | 0.114523 | 0.07095 | 254.7 |
| 2 | 10.85447 | 1.72537 | -13.7 |
| 2 | 10.55271 | 1.67889 | -16.1 |
| 2 | 10.74182 | 1.70802 | -14.6 |
| 2 | 10.95118 | 1.74027 | -13.0 |
| 2 | 10.98507 | 1.74549 | -12.7 |
| 4 | 23.49825 | 3.67307 | -8.2 |
| 4 | 22.46422 | 3.51379 | -12.2 |
| 4 | 22.98826 | 3.59451 | -10.1 |
| 4 | 23.29846 | 3.64230 | -8.9 |
| 4 | 22.80482 | 3.56625 | -10.8 |
Table 2: Validation data for regression model
It’s important to state here that the higher the number of determinations at each calibration level, the higher the confidence we can have into the results of the investigation (6 independent determinations at each concentration level is typical) and that having data at the upper and lower end of the range will also help to investigate the model more thoroughly.
The results for the standard solutions would be unusable with huge associated error. This data is typical of the situation in which the larger variance of standards at higher concentrations drastically skews the results for the determinations at lower concentration and we suspect heteroscedasticity within the data. There are two checks that might be made in this case;
1) Construct a regression model from the data in Table 2 and examine the residuals plot
2) Carry out an F-test using the highest and lowest data points in the validation data and test to see if there is a significant difference in the variances of the two populations (i.e. the data for the highest and lowest calibration standards)
The residuals plot from the regression analysis of the data is shown in Figure 2 alongside the F Test results (Table 3). All of the data was generated in Microsoft Excel using the Data Analysis Toolpack Add-In.
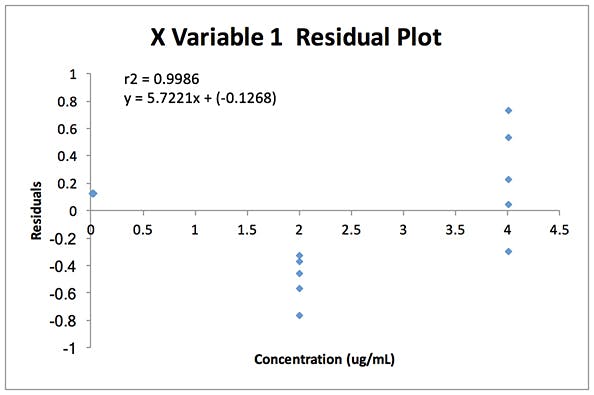
Figure 2: Residual plot for the validation data in Table 2
F-Test Two-Sample for Variances
| Variable 1 | Variable 2 |
|
| Mean | 23.01080234 | 0.055415 |
| Variance | 0.165509437 | 9.31E-07 |
| Observations | 5 | 5 |
| df | 4 | 4 |
| F | 177763.4902 | |
| P(F<=f) one-tail | 9.49357E-11 | |
| F Critical one-tail | 6.388232909 |
Table 3: F-Test result from the 0.01 and 4 μg/mL Standard data from Table 2
As can be seen from Figure 2, the residuals form a ‘fan’ shape from lower to higher concentrations and this is generally typical of heteroscedastic data in analytical calibration models, visually demonstrating the increasing variance with analyte concentration.
In order to further verify heteroscedasticity an F-test was performed using the variance of the higher concentration data (s2) versus the lower concentration data (s1) according to the following equation;
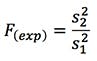
From the data shown in Table 3, it is clear that the calculated F value (177763.4902) far exceeds the critical value for F (one-tail test) (6.388232909) and therefore there is a strong indication that the variances of these two populations are not equal.
This evidence of heteroscedasticity is justification for the consideration of a weighted least squares calibration model.
The key question is, which weighting to apply and it is here that users often become discouraged due to a lack of a definitive methodology to assess the effects of the various weightings. One further discouraging factor is that Microsoft Excel does not offer a function for weighted regression – however several are available online with my favourite being found at the following link;
http://terpconnect.umd.edu/~toh/models/CalibrationCurve.html
(select the weighted linear regression spreadsheet and download it)
Note also that your data system may be capable of automatically calculating the weighted regression which will save a lot of manual data processing.
One helpful method to assess the performance of each weighting method is to measure the Σ%RE for each of the validation data points using the various weighting schemes and assess this number alongside the residual plot for each weighting. The best model will usually be that which produces the lowest Σ%RE value alongside a residual plot which shows a much more even distribution of variances across all of the concentration levels within the range. Table 4 shows this data for the unweighted and 1/x weighted data and Table 5 shows the results of the assessment of all different weighting methods.
| Std Amount (µg/ml) | Response Factor | Calculated Conc (µg/ml) (unweighted) | % Relative Error (unweighted) | Absolute % Relative Error (unweighted) | Calculated Conc (µg/ml) (1/x2 weighting) | % Relative Error (1/x2 weighting) | Absolute % Relative Error (1/x2 weighting) |
| 0.01 | 0.05481 | 0.06175 | -517.50504 | 517.50504 | 0.01046 | -4.61872 | 4.61872 |
| 0.01 | 0.05683 | 0.06206 | -520.61093 | 520.61093 | 0.01084 | -8.41356 | 8.41356 |
| 0.01 | 0.05459 | 0.06172 | -517.17166 | 517.17166 | 0.01042 | -4.21140 | 4.21140 |
| 0.01 | 0.05601 | 0.06194 | -519.35372 | 519.35372 | 0.01069 | -6.87748 | 6.87748 |
| 0.01 | 0.05483 | 0.06175 | -517.54171 | 517.54171 | 0.01047 | -4.66353 | 4.66353 |
| 0.02 | 0.11498 | 0.07102 | -255.09692 | 255.09692 | 0.02179 | -8.93390 | 8.93390 |
| 0.02 | 0.11437 | 0.07093 | -254.62566 | 254.62566 | 0.02167 | -8.35810 | 8.35810 |
| 0.02 | 0.11092 | 0.07039 | -251.96977 | 251.96977 | 0.02102 | -5.11308 | 5.11308 |
| 0.02 | 0.11422 | 0.07090 | -254.51138 | 254.51138 | 0.02164 | -8.21847 | 8.21847 |
| 0.02 | 0.11452 | 0.07095 | -254.74463 | 254.74463 | 0.02170 | -8.50347 | 8.50347 |
| 2 | 10.85447 | 1.72537 | 13.73131 | 13.73131 | 2.04311 | -2.15555 | 2.15555 |
| 2 | 10.55271 | 1.67889 | 16.05554 | 16.05554 | 1.98632 | 0.68424 | 0.68424 |
| 2 | 10.74182 | 1.70802 | 14.59898 | 14.59898 | 2.02191 | -1.09541 | 1.09541 |
| 2 | 10.95118 | 1.74027 | 12.98643 | 12.98643 | 2.06131 | -3.06565 | 3.06565 |
| 2 | 10.98507 | 1.74549 | 12.72537 | 12.72537 | 2.06769 | -3.38463 | 3.38463 |
| 4 | 23.49825 | 3.67307 | 8.17319 | 8.17319 | 4.42285 | -10.57123 | 10.57123 |
| 4 | 22.46422 | 3.51379 | 12.15533 | 12.15533 | 4.22823 | -5.70577 | 5.70577 |
| 4 | 22.98826 | 3.59451 | 10.13719 | 10.13719 | 4.32686 | -8.17156 | 8.17156 |
| 4 | 23.29846 | 3.64230 | 8.94259 | 8.94259 | 4.38525 | -9.63116 | 9.63116 |
| 4 | 22.80482 | 3.56625 | 10.84366 | 10.84366 | 4.29234 | -7.30840 | 7.30840 |
| Σ%RE= | 3983.48 | Σ%RE= | 119.68532 |
Table 4: Assessment of Σ%RE for unweighted and 1/x2 weighted least squares regression models for the validation data of Table 2
| Weighting | m | c | r2 | Σ%RE |
| Unweighted | 6.4916 | -0.34605 | 0.9980 | 3983.5 |
| 1/x | 6.2131 | -0.00470 | 0.9939 | 140.9 |
| 1/x2 | 5.3131 | -0.00077 | 0.9869 | 119.7 |
| 1/y | 6.1697 | -0.00417 | 0.9931 | 134.3 |
| 1/y2 | 5.1851 | -0.00059 | 0.9884 | 167.9 |
Table 5: Results from the assessment of various calibration models using the validation data of Table 2
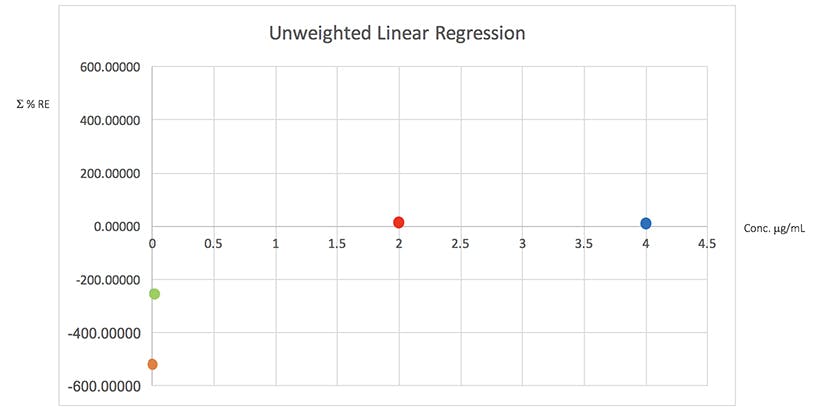
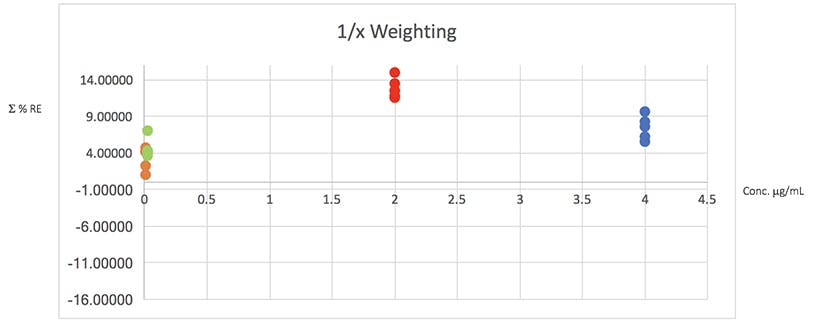
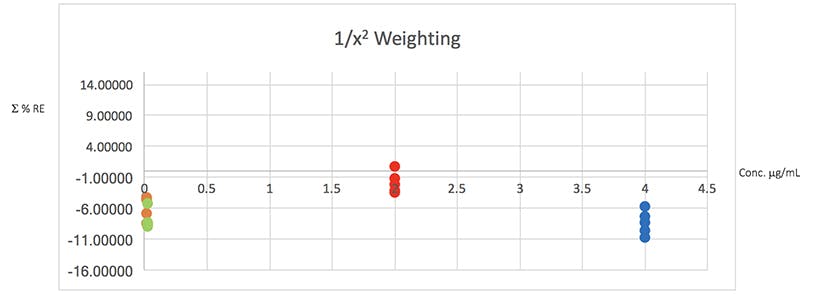
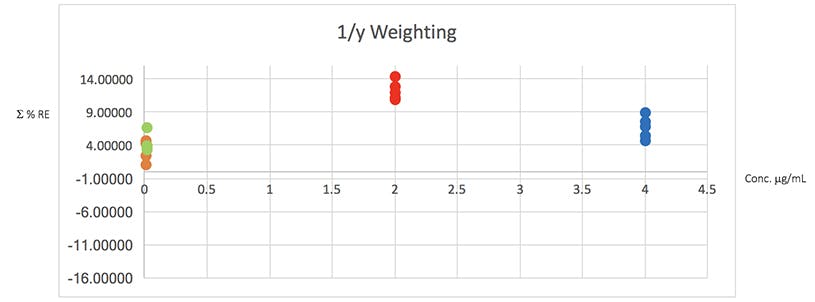
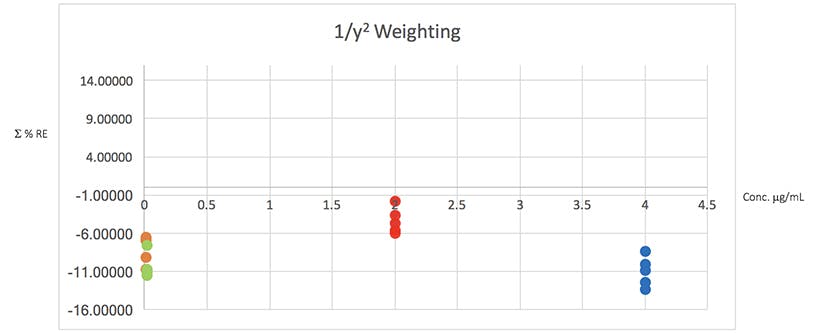
Figure 4: Plots of total error in the determination of the validation data of Table 2 using various weighted least squares regression models, used to assess the distribution of error across the range of concentrations
From Table 5 it would seem that the 1/x2 weighting produces the lowest Σ%RE and Figure 4 helps to highlight the problem with the unweighted data and indicates a more even distribution of variance across of the calibration concentrations. I believe that this is strong evidence to justify the use of the 1/x2 weighted least squares regression model for this determination.
It should be noted that whilst in this example the error plots do not greatly differ on visual examination, in some examples they can be vital in helping to choose the correct model and justifying the approach.
Of course this is only one facet of the investigation of the calibration model statistics and one might argue that the regression data may indicate that non-linear effects are observed (the U shape of the residuals data in Figure 2). Next time we shall investigate the goodness of fit for linear versus quadratic calibration curves to help define the most appropriate calibration model.
Related articles